Should work fine. To test this, I just added a function to my custom App’s hooks.py
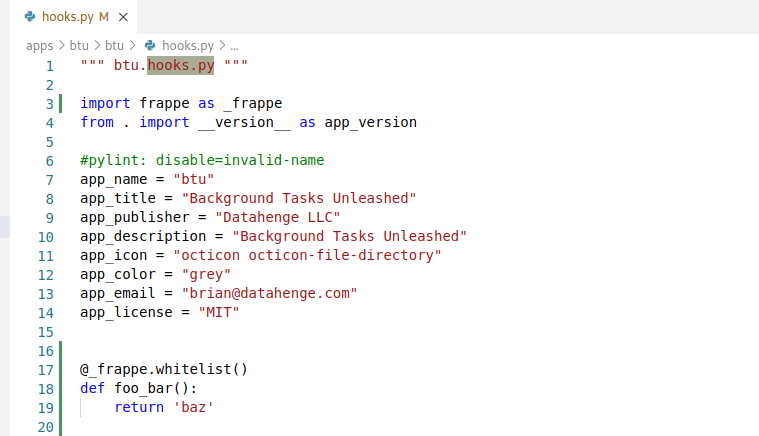
To call this API method, here’s the curl I used.
curl --request GET \
--url http://127.0.0.1:8000/api/method/btu.hooks.foo_bar \
--header 'Authorization: token abcdef:123456' \
--header 'Content-Type: application/json' \
--cookie 'sid=Guest; system_user=yes; full_name=Guest; user_id=Guest; user_image='
And I receive this response:
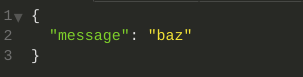
(Note, I’m using actually not using curl, I’m using Insomnia. But you can use curl from a shell terminal, or Postman, or whatever REST client you like.)
Digress
Now, I don’t want to confuse matters. However…since we’re already talking about ‘hooks.py’. Did you notice how I imported the frappe module in a really weird way? I wrote this:
import frappe as _frappe
instead of this:
import frappe
This has nothing to do with API calls. But it’s an important “pitfall” when working with hooks.py. Whenever doing imports into ‘hooks.py’ specifically? Alias them. The reasons “why” are complex. It has to do with how Frappe framework automatically executes ‘hooks.py’ code in the background, and Python pickling.
If you import in the usual way, with 'import frappe'. Then your code won’t run, and you’ll get an obscure message about pickling. Here’s the article where I learned about this little trick:
(for better or worse, I’ve had to interact with Python pickling a lot more, since then)