Hi,
I https my site, with certbot (using the tutorial in its website), and after that, my site went too slow.
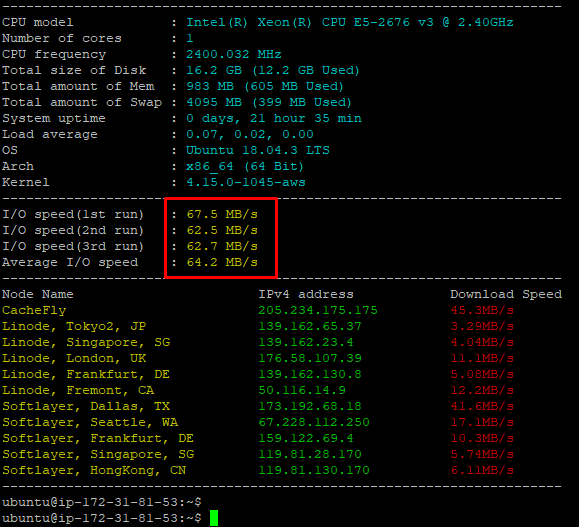
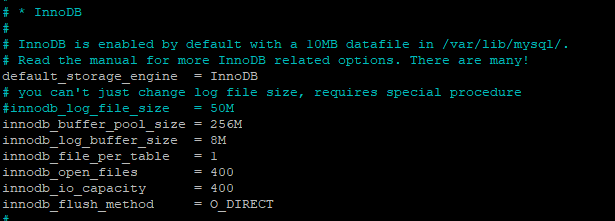
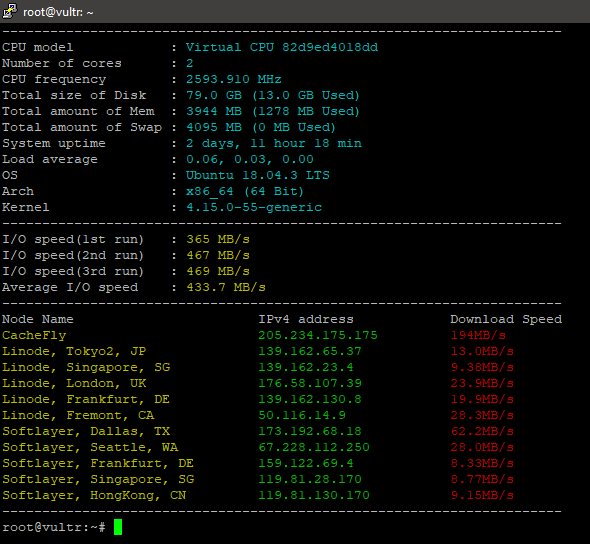
I’m running an EC2 AWS host, with ubuntu 18, install an ERPNext with python3.
I already checked the log files as shown on this post, and they are short.
My fail2ban:
/var/log/fail2ban.log {
weekly
rotate 4
compress
delaycompress
missingok
postrotate
#fail2ban-client flushlogs 1>/dev/null
fail2ban-client flushlogs 1>/dev/null || true
endscript
# If fail2ban runs as non-root it still needs to have write access
# to logfiles.
# create 640 fail2ban adm
create 640 root adm
}
Not sure if the logs are rotated.
Now, when I try to restart nginx, I’ve got this message:
Job for nginx.service failed because the control process exited with error code.
See “systemctl status nginx.service” and “journalctl -xe” for details.
and, with systemctl:
Job for nginx.service failed because the control process exited with error code.
See "systemctl status nginx.service" and "journalctl -xe" for details.
frappe@ip-172-31-81-53:~/frappe-bench$ ^C
frappe@ip-172-31-81-53:~/frappe-bench$ sudo systemctl status nginx.service
● nginx.service - A high performance web server and a reverse proxy server
Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Tue 2019-08-20 17:01:34 UTC; 42s ago
Docs: man:nginx(8)
Process: 2881 ExecStop=/sbin/start-stop-daemon --quiet --stop --retry QUIT/5 --pidfile /run/nginx.pid (code=exited, status=2)
Process: 4718 ExecStart=/usr/sbin/nginx -g daemon on; master_process on; (code=exited, status=1/FAILURE)
Process: 4711 ExecStartPre=/usr/sbin/nginx -t -q -g daemon on; master_process on; (code=exited, status=0/SUCCESS)
Main PID: 849 (code=exited, status=0/SUCCESS)
Aug 20 17:01:31 ip-172-31-81-53 systemd[1]: Starting A high performance web server and a reverse proxy server...
Aug 20 17:01:31 ip-172-31-81-53 nginx[4718]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
Aug 20 17:01:32 ip-172-31-81-53 nginx[4718]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
Aug 20 17:01:32 ip-172-31-81-53 nginx[4718]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
Aug 20 17:01:33 ip-172-31-81-53 nginx[4718]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
Aug 20 17:01:33 ip-172-31-81-53 nginx[4718]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
Aug 20 17:01:34 ip-172-31-81-53 nginx[4718]: nginx: [emerg] still could not bind()
Aug 20 17:01:34 ip-172-31-81-53 systemd[1]: nginx.service: Control process exited, code=exited status=1
Aug 20 17:01:34 ip-172-31-81-53 systemd[1]: nginx.service: Failed with result 'exit-code'.
Aug 20 17:01:34 ip-172-31-81-53 systemd[1]: Failed to start A high performance web server and a reverse proxy server.
Any hints?