Hello community
i am on ERPNext: v12.0.6 (version-12)
Frappe Framework: v12.0.6 (version-12)
i have this error msg when i’m trying importing csv file for chart of account with Arabic language in it
UnicodeDecodeError: 'utf8' codec can't decode byte 0xe3 in position 0: invalid continuation byte
Are there any ideas to help
Are there any suggestions ?
This was because you made changes to the file and its encoding. You could also try to change the encoding of the file to utf-8 using any editor in ubuntu as it provides directory option to change encoding. If problem remains then try to undo all the changes made to the file or change the directory.
Hope this helps
I need to change encoding, because typing account names in Arabic will appear as question marks if I don’t.
Show me how do make the changing, please.
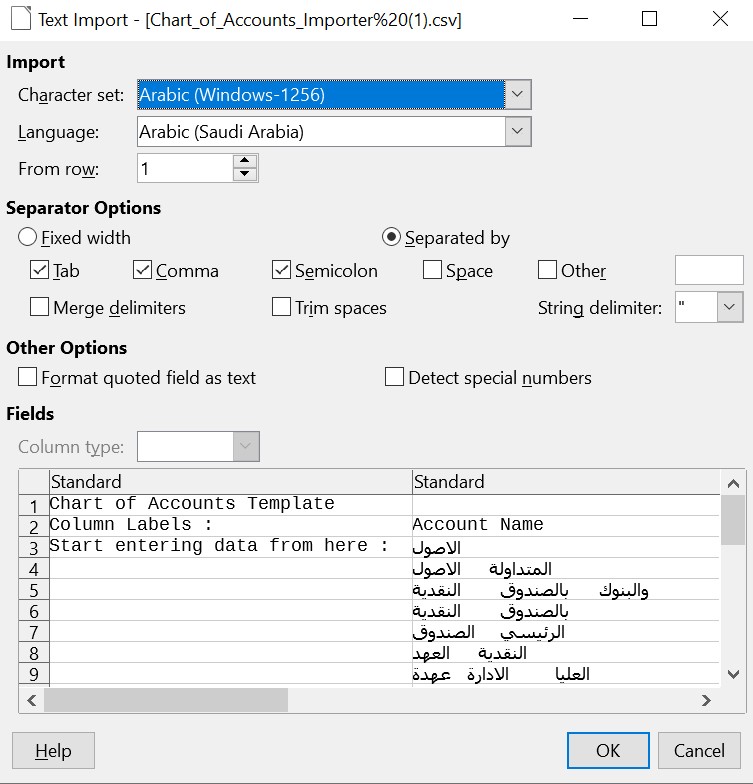
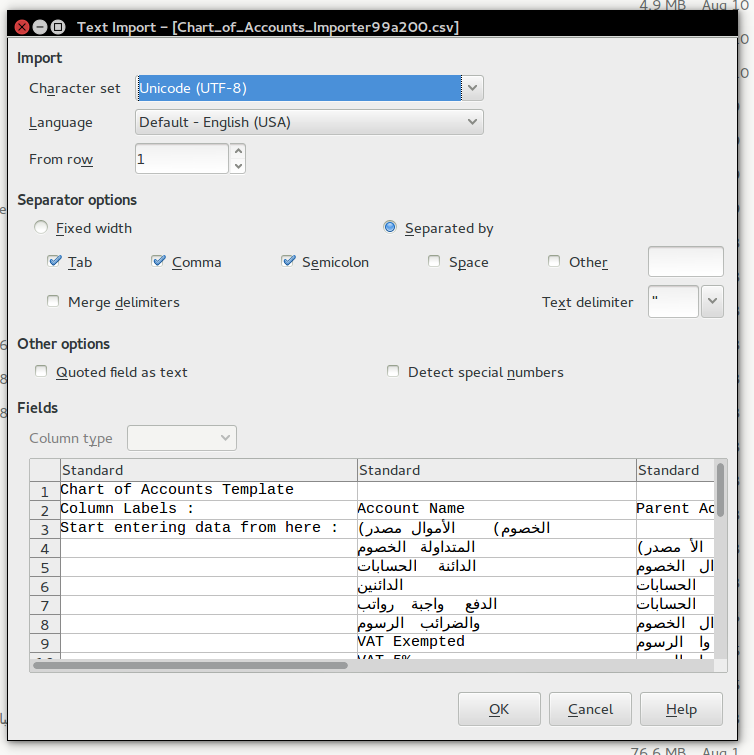
I downloaded the template file and opened it using libreoffice
Then I set the encoding settings like the following image:
You have to change character set to this:
3 Likes
Thank you so much
It worked
Unicode String types are a handy Python feature that allows you to decode encoded Strings and forget about the encoding until you need to write or transmit the data. Python tries to convert a byte-array (a bytes which it assumes to be a utf-8-encoded string) to a unicode string (str). This process of course is a decoding according to utf-8 rules. When it tries this, it encounters a python byte sequence which is not allowed in utf-8-encoded strings (namely this 0xff at position 0). One simple way to avoid this error is to encode such strings with encode() function as follows (if a is the string with non-ascii character):
a.encode('utf-8').strip()
Or
Use encoding format ISO-8859-1 to solve the issue.