Hi, I am trying to run ERPNext on my vanilla Kubernetes cluster (Longhorn storage class). The RAM is 4GB on worker nodes, so it should be enough for starting the pods. However, my pods are stuck in container creation for some reason.
nfs-common and open-iscsi are already installed on the system (Ubuntu 22.04).
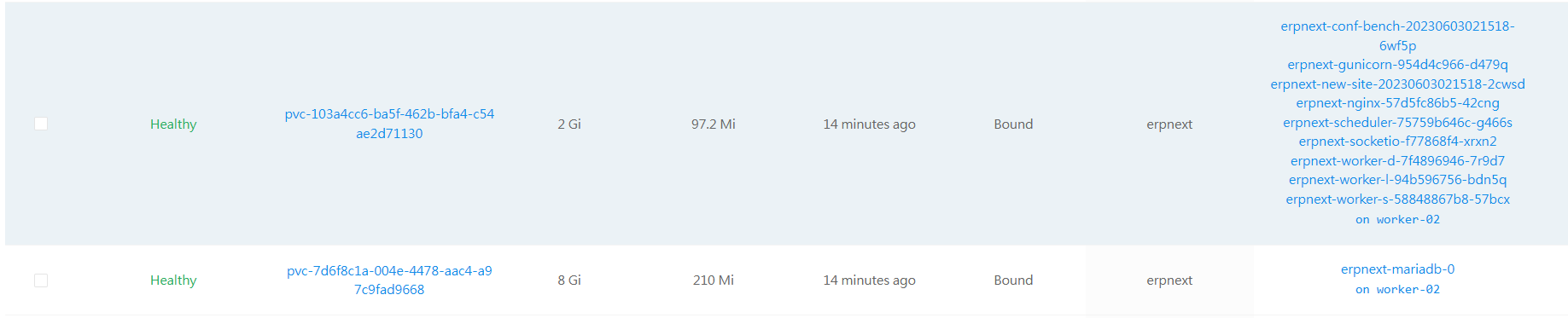
The state of pods:
root@control-plane-01:~# kubectl get pods -n erpnext -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
erpnext-conf-bench-20230603021518-6wf5p 0/1 Init:0/1 0 11m <none> worker-02 <none> <none>
erpnext-gunicorn-954d4c966-d479q 0/1 ContainerCreating 0 11m <none> worker-02 <none> <none>
erpnext-mariadb-0 1/1 Running 0 11m 10.244.37.208 worker-02 <none> <none>
erpnext-new-site-20230603021518-2cwsd 0/1 Init:0/1 0 11m <none> worker-02 <none> <none>
erpnext-nginx-57d5fc86b5-42cng 0/1 ContainerCreating 0 11m <none> worker-02 <none> <none>
erpnext-redis-cache-master-0 1/1 Running 0 11m 10.244.37.210 worker-02 <none> <none>
erpnext-redis-queue-master-0 1/1 Running 0 11m 10.244.37.207 worker-02 <none> <none>
erpnext-redis-socketio-master-0 1/1 Running 0 11m 10.244.37.204 worker-02 <none> <none>
erpnext-scheduler-75759b646c-g466s 0/1 ContainerCreating 0 11m <none> worker-02 <none> <none>
erpnext-socketio-f77868f4-xrxn2 0/1 ContainerCreating 0 11m <none> worker-02 <none> <none>
erpnext-worker-d-7f4896946-7r9d7 0/1 ContainerCreating 0 11m <none> worker-02 <none> <none>
erpnext-worker-l-94b596756-bdn5q 0/1 ContainerCreating 0 11m <none> worker-02 <none> <none>
erpnext-worker-s-58848867b8-57bcx 0/1 ContainerCreating 0 11m <none> worker-02 <none> <none>
Here are the events of one of some pods:
kubectl describe pod -n erpnext erpnext-worker-s-58848867b8-57bcx
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 11m default-scheduler 0/3 nodes are available: pod has unbound immediate PersistentVolumeClaims. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod..
Normal Scheduled 11m default-scheduler Successfully assigned erpnext/erpnext-worker-s-58848867b8-57bcx to worker-02
Normal SuccessfulAttachVolume 11m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-103a4cc6-ba5f-462b-bfa4-c54ae2d71130"
Warning FailedMount 7m21s (x2 over 11m) kubelet MountVolume.MountDevice failed for volume "pvc-103a4cc6-ba5f-462b-bfa4-c54ae2d71130" : rpc error: code = Internal desc = mount failed: exit status 32
Mounting command: /usr/local/sbin/nsmounter
Mounting arguments: mount -t nfs -o vers=4.1,noresvport,intr,hard 10.101.5.17:/pvc-103a4cc6-ba5f-462b-bfa4-c54ae2d71130 /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/c8b8a3cf2d8fbd6b7f6d63fcfe39d8939a9370d6c7120928f6faf96cb6666df1/globalmount
Output: mount: /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/c8b8a3cf2d8fbd6b7f6d63fcfe39d8939a9370d6c7120928f6faf96cb6666df1/globalmount: bad option; for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
kubectl describe pod -n erpnext erpnext-scheduler-75759b646c-g466s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 12m default-scheduler 0/3 nodes are available: pod has unbound immediate PersistentVolumeClaims. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod..
Normal Scheduled 12m default-scheduler Successfully assigned erpnext/erpnext-scheduler-75759b646c-g466s to worker-02
Normal SuccessfulAttachVolume 12m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-103a4cc6-ba5f-462b-bfa4-c54ae2d71130"
Warning FailedMount 108s (x5 over 10m) kubelet Unable to attach or mount volumes: unmounted volumes=[sites-dir], unattached volumes=[], failed to process volumes=[]: timed out waiting for the condition
Warning FailedMount 28s (x3 over 12m) kubelet MountVolume.MountDevice failed for volume "pvc-103a4cc6-ba5f-462b-bfa4-c54ae2d71130" : rpc error: code = Internal desc = mount failed: exit status 32
Mounting command: /usr/local/sbin/nsmounter
Mounting arguments: mount -t nfs -o vers=4.1,noresvport,intr,hard 10.101.5.17:/pvc-103a4cc6-ba5f-462b-bfa4-c54ae2d71130 /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/c8b8a3cf2d8fbd6b7f6d63fcfe39d8939a9370d6c7120928f6faf96cb6666df1/globalmount
Output: mount: /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/c8b8a3cf2d8fbd6b7f6d63fcfe39d8939a9370d6c7120928f6faf96cb6666df1/globalmount: bad option; for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
From the perspective of Longhorn, the volumes seem to be attached successfully. So the RWX seems to be working.
Does anybody have an idea what the issue could be?
I may provide access to the cluster if needed (just a test cluster).