I have a v13 running in prod mode on an AWS instance.
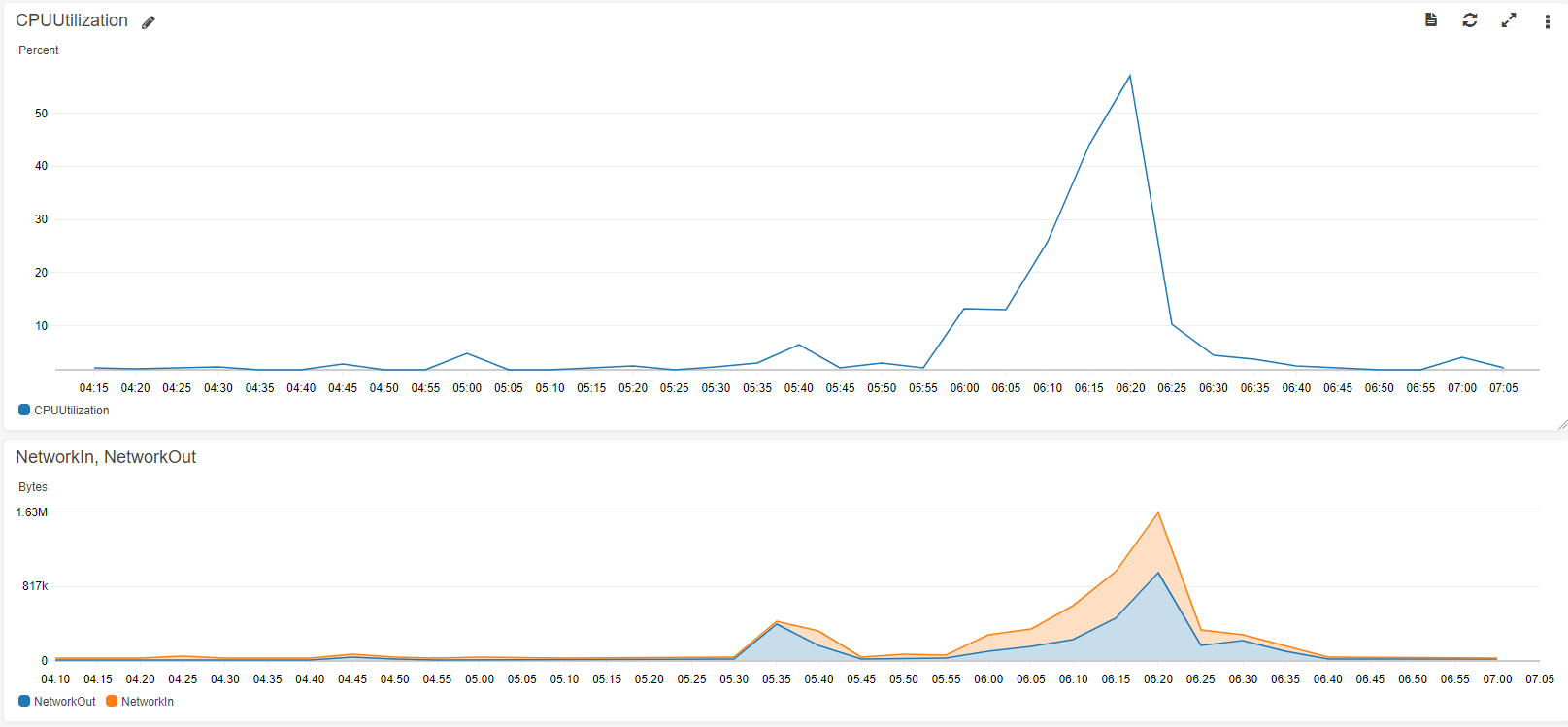
Sometimes (like once every two-three weeks) the CPU and network load spikes, see attached image from AWS cloudwatch. As a result the UI gets very slow…
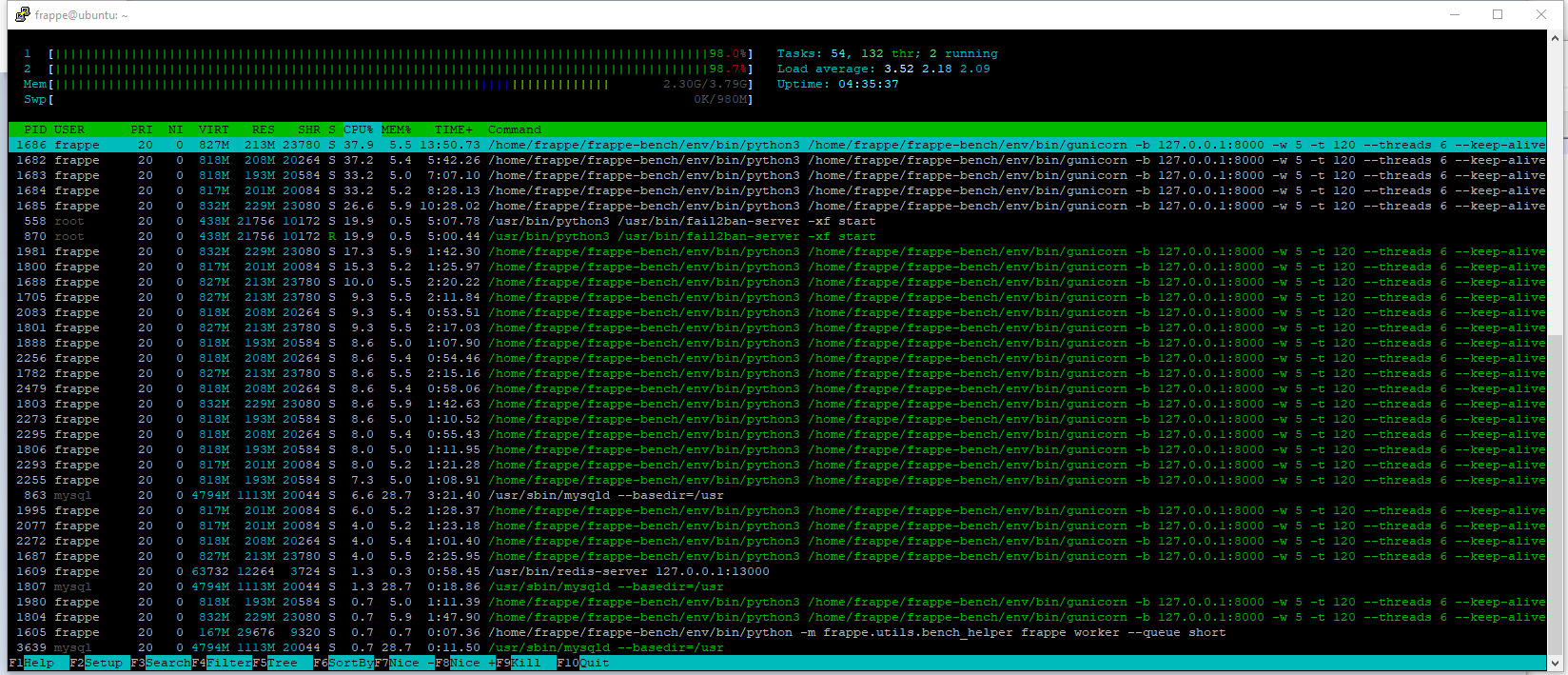
Does it happen at the same time of day every time? If you are able to ssh into the instance while its happening, just open htop and check what’s running.
Does this occur recurrently? or is it random? do you have custom background jobs on your instance? you can take a look at the background jobs if the spike occurs recurrently.
edit: running on AWS t3.medium, 2 CPUs 4GB of RAM. do I need to take something bigger?
never more than 5-10 users concurrently online… are the gunicorn parameters wrong?
I think there is a proble in version 13 am having the same issess. Am running v11 for 3 years with over 15 customer with different database on t2.medium and this never happen. When i upgrade to v13 this start moving very slow.