After migrating from stand alone setup to EKS, we have been encountering http_timeout error. We used to update the timeout frequency to 6000 instead of the default value using the bench config http_timeout 6000.
How do I update the same in the eks environment? I tried the same in gunicorn pod and was able to see the changes were updated in the common_site_config.json but I still see issue when there is a bulk update.
Request someone from the community provide further guidance on how to troubleshoot this issue?
Set env var PROXY_READ_TIMEOUT for nginx deployment:
more about env vars: frappe_docker/docs/environment-variables.md at main · frappe/frappe_docker · GitHub
Hi @revant_one the fix was applied to the nginx deployment and had redeployed the image, but the issue still exists. I was able to trace the new changes made for the nginx deployment in the values.yaml when the application was deployed. Also, I could see the changes in gunicorn pod (frappe-bench/sites/common_site_config.json) as well.

Issue screenshot after updating the env variable and redeploying the image.
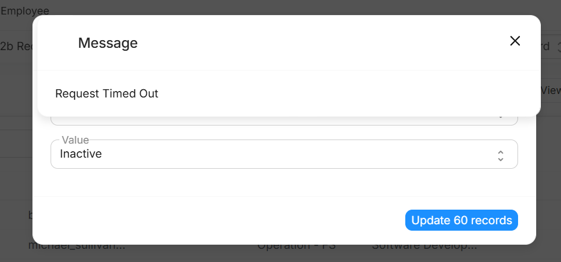
Is it only the env variable change that needs to be taken care of or should there be any additional steps to have this up and running?
- Timeout from site_config.json or common_site_config.json is later used to generate nginx config on a VM. It does not have any use in containerized environment
- You need to generate the container’s nginx config using environment variables or mount a custom one and use that.
Share your nginx section from values.yaml
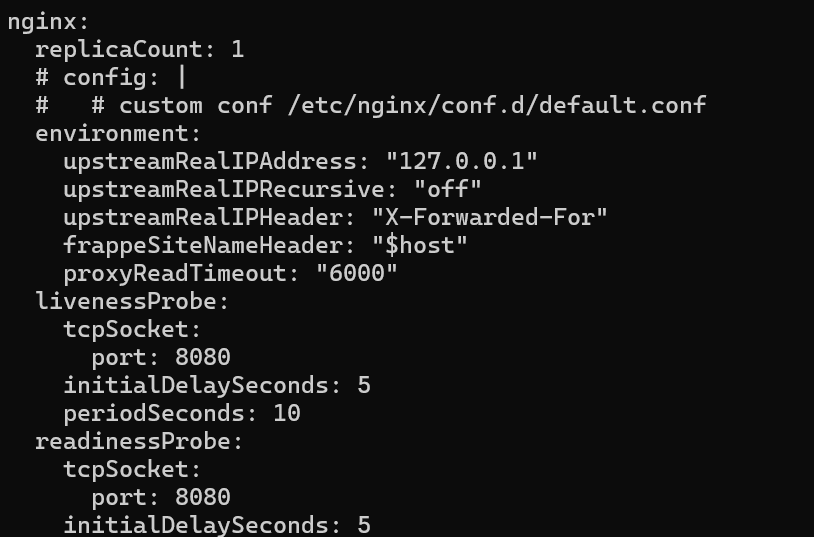
http_timeout in site_config.json and nginx config is also correct
Try extending the gunicorn --timeout, do that by passing custom command in worker.gunicorn.args.
Default is: