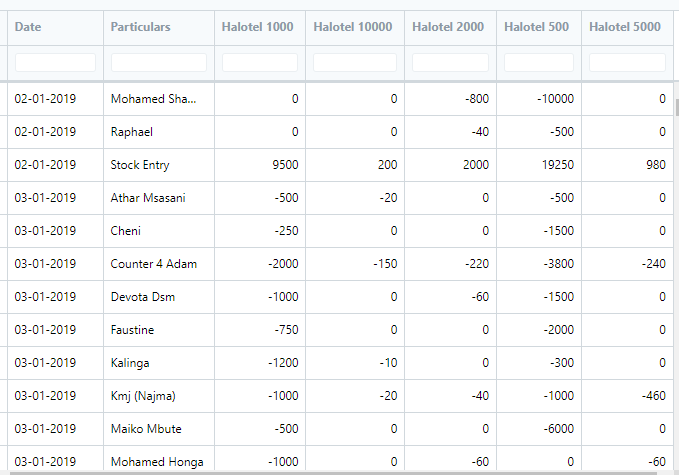
Using pandas to create pivot table using bench console with below code.
File “/home/frappe/frappe-bench/apps/csf_tz/csf_tz/csf_tz/report/itemwise_stock_movement/itemwise_stock_movement.py”, line 25, in execute
pvt = pd.pivot_table(df,index=[“posting_date”,“Particulars”],values=[“actual_qty”],columns=[“item_code”],aggfunc=[np.sum], fill_value=0)
File “/home/frappe/frappe-bench/env/local/lib/python2.7/site-packages/pandas/core/reshape/pivot.py”, line 41, in pivot_table
margins=margins, margins_name=margins_name)
File “/home/frappe/frappe-bench/env/local/lib/python2.7/site-packages/pandas/core/reshape/pivot.py”, line 61, in pivot_table
raise KeyError(i)
KeyError: u’actual_qty’
but when I run it in the report and load using front end it gives KeyError.
If we can overcome this error, we can have a lot of ease in making report using pandas
List of DIctionaries is as below.
[{u’Particulars’: u’Mohamed Shamshu’,
u’actual_qty’: -800.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Mohamed Shamshu’,
u’actual_qty’: -10000.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Raphael’,
u’actual_qty’: -40.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Raphael’,
u’actual_qty’: -500.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Stock Entry’,
u’actual_qty’: 9500.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Stock Entry’,
u’actual_qty’: 200.0,
u’item_code’: u’Halotel 10000’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Stock Entry’,
u’actual_qty’: 2000.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Stock Entry’,
u’actual_qty’: 19250.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Stock Entry’,
u’actual_qty’: 980.0,
u’item_code’: u’Halotel 5000’,
u’posting_date’: datetime.date(2019, 1, 2)},
{u’Particulars’: u’Athar Msasani’,
u’actual_qty’: -500.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Athar Msasani’,
u’actual_qty’: -20.0,
u’item_code’: u’Halotel 10000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Athar Msasani’,
u’actual_qty’: -500.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Cheni’,
u’actual_qty’: -250.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Cheni’,
u’actual_qty’: -1500.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Counter 4 Adam’,
u’actual_qty’: -2000.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Counter 4 Adam’,
u’actual_qty’: -150.0,
u’item_code’: u’Halotel 10000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Counter 4 Adam’,
u’actual_qty’: -220.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Counter 4 Adam’,
u’actual_qty’: -3800.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Counter 4 Adam’,
u’actual_qty’: -240.0,
u’item_code’: u’Halotel 5000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Devota Dsm’,
u’actual_qty’: -1000.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Devota Dsm’,
u’actual_qty’: -60.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Devota Dsm’,
u’actual_qty’: -1500.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Faustine’,
u’actual_qty’: -750.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Faustine’,
u’actual_qty’: -2000.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kalinga’,
u’actual_qty’: -1200.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kalinga’,
u’actual_qty’: -10.0,
u’item_code’: u’Halotel 10000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kalinga’,
u’actual_qty’: -300.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kmj (Najma)‘,
u’actual_qty’: -1000.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kmj (Najma)‘,
u’actual_qty’: -20.0,
u’item_code’: u’Halotel 10000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kmj (Najma)‘,
u’actual_qty’: -40.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kmj (Najma)‘,
u’actual_qty’: -1000.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Kmj (Najma)‘,
u’actual_qty’: -460.0,
u’item_code’: u’Halotel 5000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Maiko Mbute’,
u’actual_qty’: -500.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Maiko Mbute’,
u’actual_qty’: -6000.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Mohamed Honga’,
u’actual_qty’: -1000.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Mohamed Honga’,
u’actual_qty’: -60.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Mohamed Honga’,
u’actual_qty’: -60.0,
u’item_code’: u’Halotel 5000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Mohamed Shamshu’,
u’actual_qty’: -6000.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Mohamed Shamshu’,
u’actual_qty’: -300.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Mohamed Shamshu’,
u’actual_qty’: -15000.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Mohamed Shamshu’,
u’actual_qty’: -200.0,
u’item_code’: u’Halotel 5000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Purchase Receipt’,
u’actual_qty’: 10000.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Purchase Receipt’,
u’actual_qty’: 100.0,
u’item_code’: u’Halotel 10000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Purchase Receipt’,
u’actual_qty’: 1000.0,
u’item_code’: u’Halotel 2000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Purchase Receipt’,
u’actual_qty’: 40000.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Purchase Receipt’,
u’actual_qty’: 500.0,
u’item_code’: u’Halotel 5000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Raphael’,
u’actual_qty’: -2100.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Raphael’,
u’actual_qty’: -4900.0,
u’item_code’: u’Halotel 500’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Raphael’,
u’actual_qty’: -40.0,
u’item_code’: u’Halotel 5000’,
u’posting_date’: datetime.date(2019, 1, 3)},
{u’Particulars’: u’Solar Kiosk’,
u’actual_qty’: -2500.0,
u’item_code’: u’Halotel 1000’,
u’posting_date’: datetime.date(2019, 1, 3)}]
The code works from bench console, but running it from report .py file it gives error