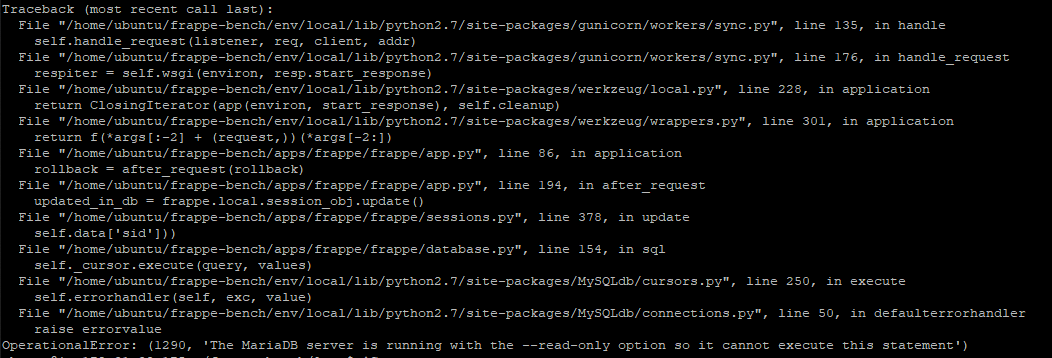
Off late we started receiving screenshots like below from our ground operations team -

Request Timed Out
While submitting sales order, sales invoice, purchase order, purchase receipt, stock entry etc…
With further investigation we realised that whenever someone ran Stock balance report this problem was coming and we were able to reproduce it every time thereafter.
The output of mysqladmin -u root -p -i 2 processlist showed the database query is taking a lot of time and mysql threads were in following states most of the times -
Copying to tmp table
Sending data
While the stock balance report was fetching required data from database, all other transaction requests were getting queued and eventually timed out.
It made sense to segregate READ (Reporting) and WRITE (Transactional) calls and direct them to different databases as a first measure so that our transactional requests have a clear passage and they do not time out. Idea was to setup mysql replication and divert all reporting calls to replica database instead of the primary database.
Introducing @frappe.read_only()
Couple of weeks back we had a code sprint with frappe team at our office. We implemented a support to divert ```read-only``` calls to replica database. A new function decorator ```@frappe.read_only``` is added to decorate methods which should use replica database.e.g. following method in frappe/query_report.py is now decorated as below -
@frappe.whitelist()
@frappe.read_only()
def run(report_name, filters=None, user=None):
report = get_report_doc(report_name)
2 new attributes namely - slave_host and use_slave_for_read_only are added in site_config.json to enable and configure the replica database -
{
"db_name": "c6b2c772b91fd3d8",
"db_password": "agYCYGfvpfrBzfDe",
"slave_host": "replica01.ntex.com",
"use_slave_for_read_only": 1
}
The @frappe.read_only() decorator wraps the method calls and alters the database connection by connecting to a replica database instead of main database as follows -
frappe/__init__.py
def read_only():
def innfn(fn):
def wrapper_fn(*args, **kwargs):
if conf.use_slave_for_read_only:
connect_read_only() <--- connects replica
With this change, our deployment architecture looked like below -
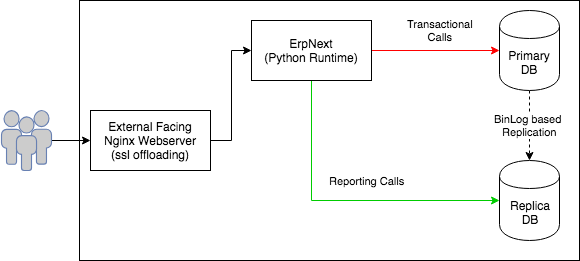
This helped us alleviate problems at our database side. However we were still sharing the the same python environment for reports and transaction calls. All HTTP requests were still piling up at a single gunicorn server.
We introduce another python runtime and updated the deployment architecture as follows -
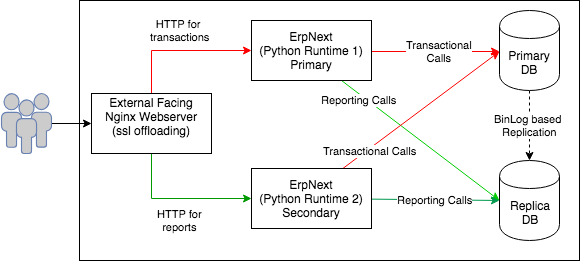
At the Nginx webserver we did URL based routing and diverted all the report calls to secondary ErpNext server. Nginx config snippet below -
location / {
if ( $arg_cmd = "frappe.desk.reportview.export_query" ) {
proxy_pass http://secondary.ntex.com;
break;
}
if ( $arg_cmd = "frappe.desk.query_report.run" ) {
proxy_pass http://secondary.ntex.com;
break;
}
proxy_pass http://primary.ntex.com;
Since frappe maintains user session information in database table, it was getting replicated to the replica server as well and users remained singed-in no matter to which ERPNext server instance they get routed to.
Ideally there should not be any transactional calls from secondary ErpNext, but on every http request, frappe updates users session in a database table. We must make this update in the primary database itself since, we were doing only 1 way replication.
We also locked down database user’s permissions on the replica db to allow only read-only operations so as to avoid any accidental updates in replica database.
Hope above commentary helps any one looking to scale up their ErpNext deployments.