Background
We have configured a few background jobs using standard ```scheduler_events``` in ```hooks.py```e.g. following custom job calculate sales projections for next day sale every night.
"daily":[
".....create_projections",
],
Similarly we have some auto email reports configured to be sent at a specific hour.
[PR to be submitted]
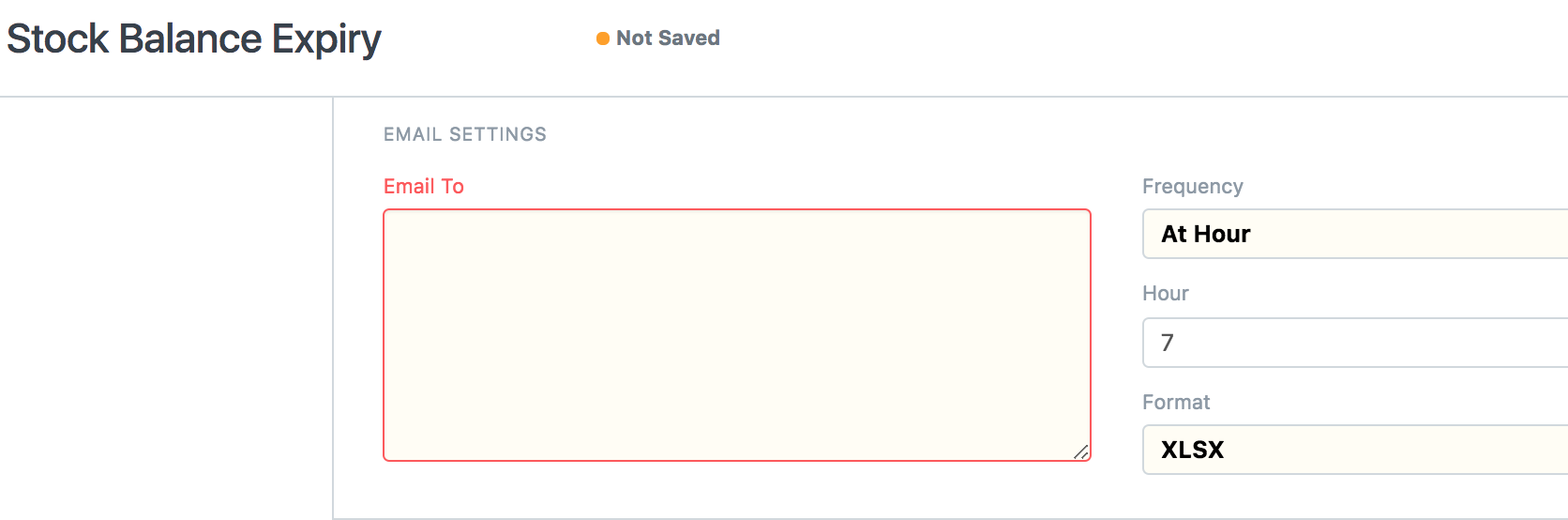
Hourly reports are sent using hourly scheduled events in hooks.py
The Issue
We are in active development and our production deployments happen quite often. Incase our servers are down at the time when the scheduled event was supposed to be triggered, it gets missed due to the downtime.Once the event is missed, there is no way it is replayed again. E.g If there was an auto emails to be sent at 4PM and server is down, those emails are never sent.
How do we build a retry mechanism to ensure guaranteed event execution?
Any inputs?