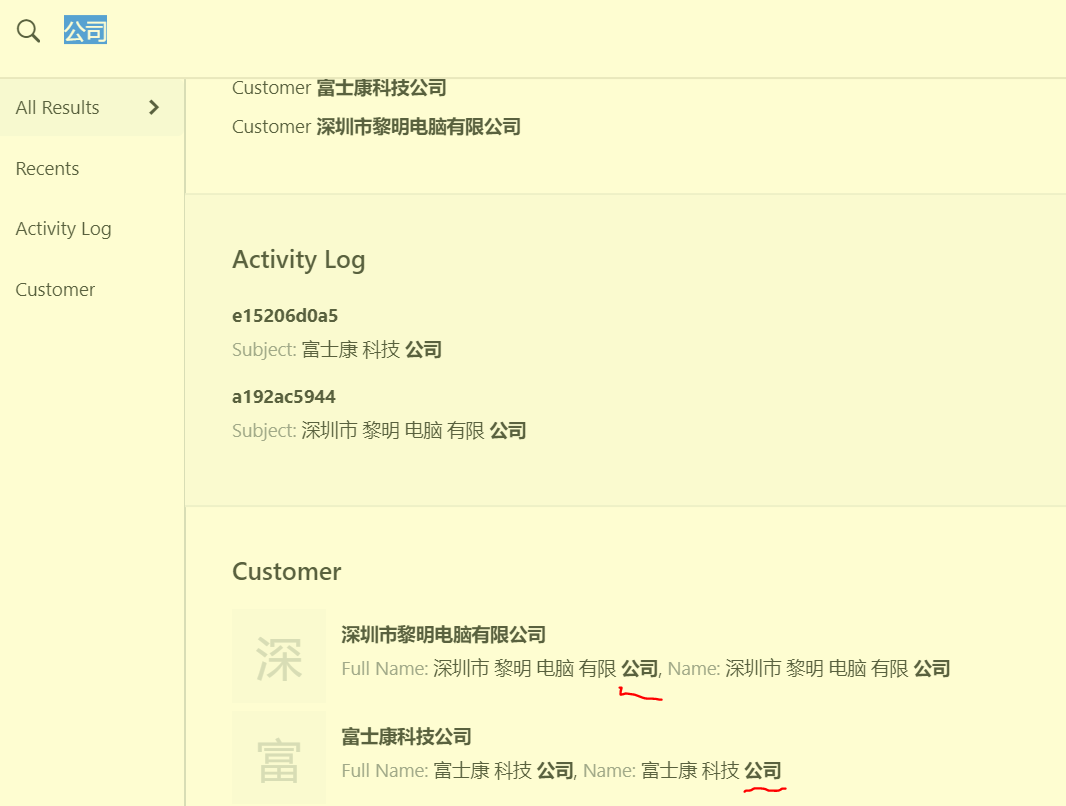
I am having trouble with the Global Search. We have many Items, Suppliers, etc with Chinese Characters and I have trouble finding them via the Global Search.
I see the same behavior on a local v11, as well as a v12 instance on erpnext.com. Can anyone advise whether there is anything on a global level what can be done to (like character encoding on the OS or database level for example?)
in any custom app hooks.py file add the below code
from frappe.utils import cint, strip_html_tags
from six import text_type
import pkuseg
seg = pkuseg.pkuseg()
from frappe.utils import global_search
def get_formatted_value(value, field):
"""
Prepare field from raw data
:param value:
:param field:
:return:
"""
from six.moves.html_parser import HTMLParser
if getattr(field, 'fieldtype', None) in ["Text", "Text Editor"]:
h = HTMLParser()
value = h.unescape(frappe.safe_decode(value))
value = (re.subn(r'<[\s]*(script|style).*?</\1>(?s)', '', text_type(value))[0])
value = ' '.join(value.split())
value = strip_html_tags(text_type(value))
try:
value = ' '.join(seg.cut(value))
except:
pass
return field.label + " : " + value
global_search.get_formatted_value = get_formatted_value
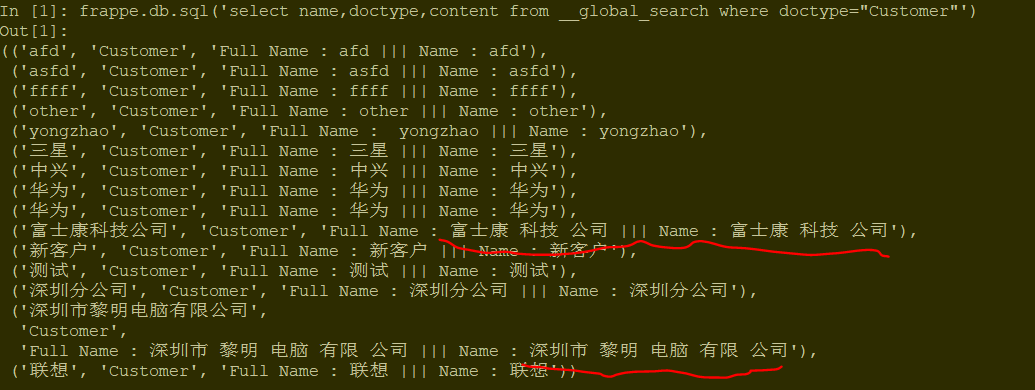
have you changed this setting and reloaded mariadb? then after this create new docs to see the result, also you can check the content by bench mariadb
then select name,doctype, content from __global_search,
oh sorry. I didn’t get that. I thought you meant, if there was any custom app, you needed to add this to that existing app’s hooks.py file. I’ll look into it and see what I can come up with.
no, if you already have existing custom app, you can add the code to the hooks.py , no problem, but you got to bench restart to make the new updated code to reload.