We are using Frappe Docker Single Server so far with multiple projects depending on the custom apps.
We create regional servers if customer asks for the same(GDPR compliance) and deploy the sites.
So far we don’t see much problem with this kind of setup.
However we are skeptical about future as our customer base increases we might hit a roadblock.
You can use existing servers for docker swarm cluster or self hosted kubernetes cluster provided servers are stopped and restarted with new setup.
You cannot use existing servers in case of managed kubernetes offering, generally you’ll have to provision nodes from provider’s api to attach them to managed cluster. There may be providers who only provide Kubernetes control-plane and allow you to attach servers from anywhere.
Yes you can, it is easy to replace ingress-nginx and use any ingress controller. It works with istio virtualservice as well.
Backup and restore is the best path for data migration
Take snapshots keep them in shared volume/pvc or push them to s3 to restore later
pull snapshots from s3 or shared volumes and restore
Use maria-backup for fast db backup and restores. If it doesn’t work for you use standard bench backup which internally uses mysqldump.
Use restic for files snapshot / restore
Run containers / pods with mounted shared volumes and access to s3 to execute the restore commands.
Infra progression
Start with Single Server (1 VM)
Move to docker swarm (1 VM), gives you nice portainer ui and web hooks for gitops/ci/automated pipelines.
Thanks for the detailed clarification @revant_one . Much needed for me at this time. Most importantly for me to know where to invest my time as we don’t want to redo everything again.
Now i understand what we should focus on
Move to docker swarm (1 VM), gives you nice portainer ui and web hooks for gitops/ci/automated pipelines.
Once we are familiar with the concepts we will move on docker swarm multi VM
@revant_one you are right. Docker Swarm is simple and easy to get started.
I should have done this before. I was assuming it to be hard to implement. But your docs helped me a lot.
for all who are using single server without portainer and swarm, i would sincerely advice to move to this setup immediately. Otherwise you will regret for all your ops effort getting spent on docker compose commands.
We have decided to use portainer and swarm.
Couple more questions:
I understood that bench commands can be executed as a stack. I can create individual stack or play around with environment variables to execute desired bench command. Is there other ways to perform bench operations?
For ease and declarative setup I’m adding stacks yaml. You add simple single containers “Tasks”, The interface in portainer needs to be used instead of yaml making it less declarative. Another way to exec into the running container from portainer ui and execute any bench commands without any tracking in yaml or portainer task. In any case make sure you only use the bench commands that don’t change the application code.
If you are exploring the docker swarm alternative, then you can create many other posts with specific questions. Link this post there for reference if you wish.
After reading all your links and with my understanding
I created a bucket my-bucket in GCP
Created a Service account
Created a HMAC
in the backup.yaml i changed the environment values like below
The job failed citing site_config.json error and unable to reach s3:https://storage.googleapis.com/my-bucket. Should i enable public access in GCP?
Where am i going wrong?
If you are looking for HA cluster? Use Kubernetes.
Choose managed Kubernetes, managed FS, managed DB, managed load balancer. You’ll achieve scale and HA with the help of cloud provider. Target users are rich, large, MNC. Business needs to be proven to fund the cloud resources.
Resources at cost are cheaper if you know how to build things from raw material. To go with self managed Kubernetes be prepared to manage much more infrastructure. Managing following infrastructure is out of scope of Frappe Framework and ERPNext.
rook.io or openebs.io or any such project for storage. Needs 4GB+ RAM per node. Turns out to be expensive (management overhead and redundancy resources). Not as expensive as managed google’s storage.
Install MariaDB Galera, on labeled nodes (dedicated part of cluster is galera cluster).
For Ingress setup MetalLB or configure cloud lb if cloud vm are used.
You may also need control-plane LB for multi-server (multi-master) setup.
If it is not managed or if you don’t have OEM support, you can go for any distribution. I’ve used k3s in containers for testing the official helm charts. Check the official helm chart tests. I’ve used kind, k3d (k3s in docker), I tried microk8s as well. All are good.
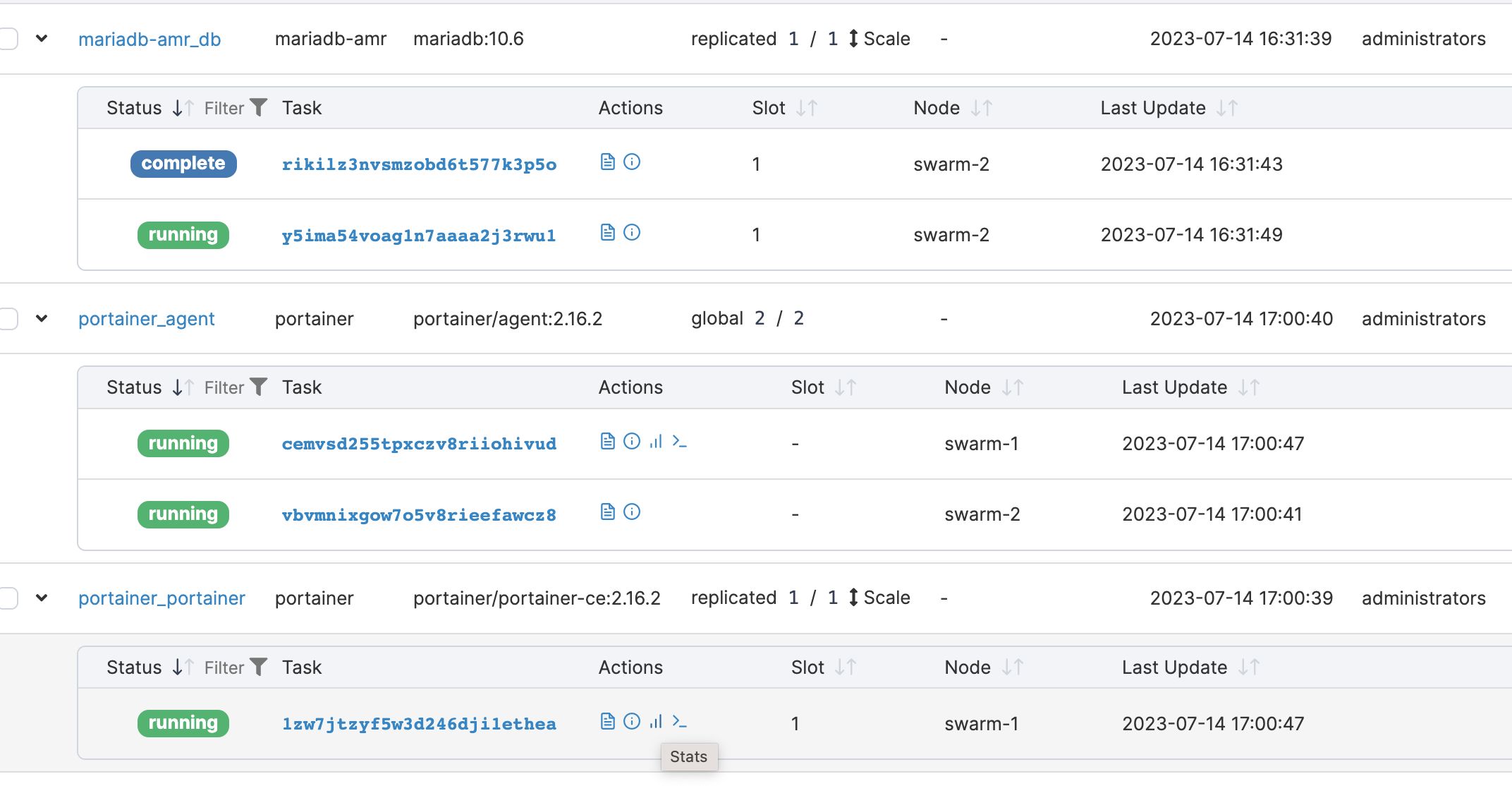
for the past few days, i upgraded the swarm with few more nodes. Deployed mariadb stack to a specific node with placement constraints. The deployment was successful as expected.
The problem here is portainer is not listing containers from other nodes.
I can access, stacks networks and services. But not containers.
Is this a limitation of portainer, or i am missing something?
The following ports must be available. On some systems, these ports are open by default.
- Port 2377 TCP for communication with and between manager nodes
- Port 7946 TCP/UDP for overlay network node discovery
- Port 4789 UDP (configurable) for overlay network traffic
Thanks @revant_one, We use GCP. Initially i allowed these ports using firewall rules. Even then we have same issue. Now for testing purpose I allowed all the ports. No improvement in the portainer. Is there something i need to do inside VM
From CLI i am able to list nodes services and tasks for the nodes
I am not sure how to list the containers for a node from manager and exec bash into it. As docker nodes ps <node_id> only lists the tasks.
From Portainer, all nodes, services and its tasks are listed. Please note the console option is disabled for tasks running from swarm2 node(worker node)
I connected to wrong IP, While docker swarm init --advertise-addr I used public static ip and used private static ip when I did docker swarm join, or other way private <-> public.
firewall or restriction on port access between nodes